Supercharge Spark Cluster With Arrow Flight Server

Apache Spark has proven itself for scalability, fault tolerance and managing massive datasets; DuckDB, on the other hand, is an in-process OLAP database, designed for single-machine, high-performance execution.
Combining the orchestration capabilities of Apache Spark with the high-performance, vectorized engine of DuckDB via the Arrow IPC format creates a powerful and efficient data processing architecture. In this article we will delve into technologies, architecture and its benefits
The setup:
Arrow Flight SQL Server:
Arrow Flight SQL is a new, high-performance protocol for interacting with SQL databases. It is a key component of the Apache Arrow ecosystem, and its primary goal is to provide a modern, efficient alternative to traditional database connectivity protocols like JDBC and ODBC.
We will be using DazzleDuck Flight Sql Server which supports planning and execution of SQL using DuckDB as execution engine. You can get more information about it at
GitHub - dazzleduck-web/dazzleduck-sql-server
Lets starts the Flight Server with Docker. The server exposes two endpoints
- HTTP on port 8080
- Arrow Flight SQL RPC on port 59307
The Docker images ships with a small data set stored at location `/data/`
docker run -ti -p 59307:59307 -p 8080:8080 dazzleduck/dazzleduck:latest
In a new terminal download and start the DuckDB and perform following
- Install and load arrow extension.
- Execute the SQL by connecting to Arrow Flight Server on port 8080; submit the query and print the results
INSTALL arrow FROM community;
LOAD arrow;
SET VARIABLE encoded_query = url_encode('FROM (FROM (VALUES(NULL::DATE, NULL::VARCHAR, NULL::VARCHAR, NULL::VARCHAR)) t( dt, p, key, value)
WHERE false
UNION ALL BY NAME
FROM read_parquet(''/data/hive_table/*/*/*.parquet'', hive_partitioning = true, hive_types = {''dt'': DATE, ''p'': VARCHAR}))');
SELECT * FROM read_arrow(concat('http://localhost:8080/query?q=', getvariable(encoded_query)));
You would see result like below.
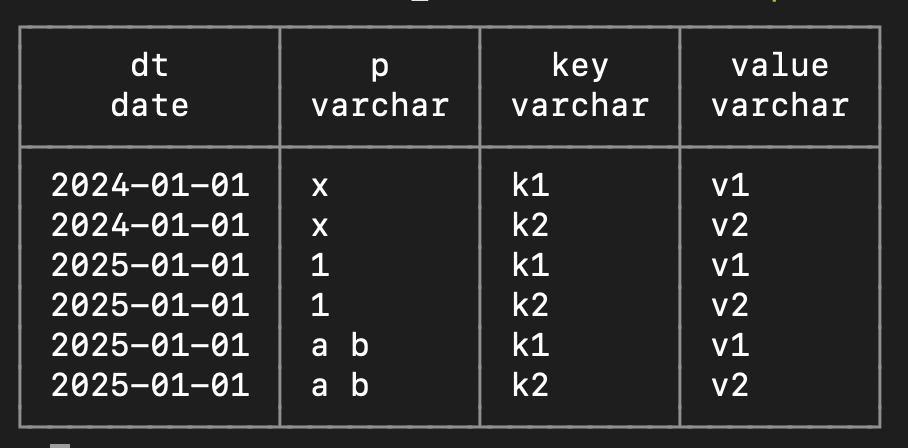
Just now you have connected to Arrow RPC Server, executed the query, collected the results and displayed it on your terminal.
Parallelization - Splitting up the Query :
Assume a query needs to read a large amount of data from multiple files that exceeds the capacity of a single DuckDB instance, the solution is to distribute the workload. In such cases we can use the planning service to split the query into smaller tasks. These splits or task then can be independently executed on different instances of Arrow Flight Server and later reduced by another engine.
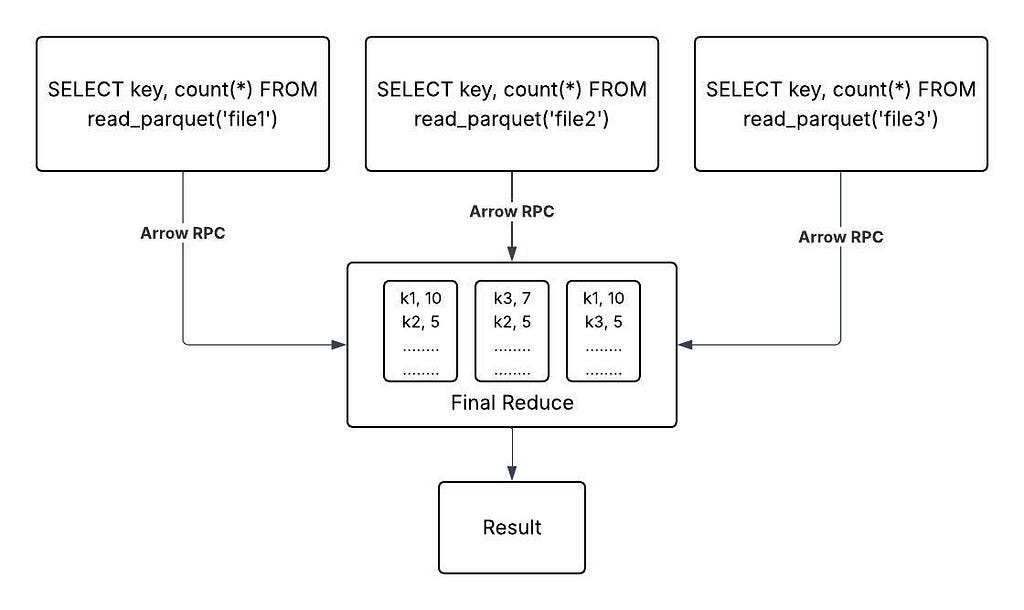
Lets look at the example with Dataset shipped with DazzleDuck Docker container. Suppose we want to execute the query
> SELECT count(*), key FROM read_parquet(‘/data/hive_table/’) GROUP BY key
In order to calculate the result for the above query we need to read three files; file1, file2, file3
Therefore the engine should be able to split this query into 3 queries
> SELECT count(*), key FROM read_parquet(‘file1’) GROUP BY key
> SELECT count(*), key FROM read_parquet(‘file2’) GROUP BY key
> SELECT count(*), key FROM read_parquet(‘file3’) GROUP BY key
Finally a reduce task should be able to take the output of these three queries and produce the required result
We can use the query splitting service of the HTTP endpoint to get the splits. This endpoint takes max files size as a parameter and produces the splits based on the parameter making sure size of the splits in kept close to the max size.
SELECT * FROM read_json(concat('http://localhost:8080/plan?split\_size=1&q=', getvariable(encoded_query)));

It returned three splits which means we can at best spit this query into 3 task and run them in parallel.
Reducer
We would need one final component which responsible for reducing the output of individual queries. Lets use Spark to perform this final step.
Spark Connector for Arrow Flight SQL:
Spark Connector for Arrow Flight SQL Server build using Spark Datasource API for interacting with Arrow Flight Server. You can get more information about it at.
GitHub - dazzleduck-web/dazzleduck-sql-spark: Arrow sql connector for spark
This Connector will be performing following
- Call Flight Server for planning and get the list of all the splits as discussed above.
- Summit those tasks/splits to executor which forwards the request to Arrow Flight Server.
- Flight Server processes these requests and return the data in Arrow IPC format
- Spark Performs final reduction which also requires data shuffle. The final calculated the results are returned to the driver
Download and Start Apache Spark Sql. Execute the command below which will also install the connector
bin/spark-sql --packages io.dazzleduck.sql:dazzleduck-sql-spark:0.0.4
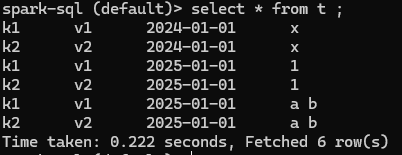
CREATE TEMP VIEW t (key string, value string, dt date, p string) using io.dazzleduck.sql.spark.ArrowRPCTableProvider options ( url = 'jdbc:arrow-flight-sql://localhost:59307?disableCertificateVerification=true&user=admin&password=admin', partition_columns 'dt, p', path '/data/hive_table', connection_timeout 'PT60m');
SELECT count(*), key FROM t GROUP BY key
The Architecture :

My Final Thought
What seems complex at first glance — adding a new layer like an Arrow Flight SQL server — actually simplifies and optimizes the entire data landscape, particularly for multi-cloud and distributed environments.
1. Multi-Cloud and On-Premise Interoperability
This is a killer use case for Arrow Flight SQL. It acts as a “lingua franca” for data across different environments.
- The Problem: Without a standardized, high-performance protocol, accessing large analytical datasets between different cloud providers (e.g., AWS S3 to Google Cloud Storage) or from on-premise data centers to the cloud is slow, expensive, and fragile. Each environment has its own native data transfer mechanisms, often requiring a lot of custom scripting and data format conversions (e.g., from Parquet to Avro).
- The Arrow Flight SQL Solution: An Arrow Flight SQL server acts as a universal gateway. It doesn’t matter if the underlying data is in an on-premise Oracle database, a data lake on Azure, or a data warehouse on AWS. The Arrow Flight SQL server presents a single, consistent, and highly optimized API. The data is exchanged in the Arrow IPC format, which is a high-bandwidth, zero-copy format. This eliminates the need for costly data conversions and allows data to flow seamlessly between any two systems that speak the protocol, regardless of their location. This not only speeds up data movement but also simplifies data governance and pipeline management.
2. Centralized Common Functionality (Caching, Security, and Access Control)
This is a huge benefit that moves critical enterprise functionality out of individual applications and into the infrastructure.
- Caching: By implementing a caching layer at the Arrow Flight SQL server level, you can transparently accelerate queries for all connected clients. A user in one department queries a dataset, and the server caches the Arrow-native result set. When a second user or a different application queries the same data, the server can deliver the result instantly from the cache without re-executing the query against the underlying database. This dramatically reduces query latency and offloads work from the core data platform, leading to massive cost savings.
- Access Control: The Arrow Flight SQL protocol includes built-in support for security features like TLS encryption and token-based authentication. An organization can centralize its data access policies at the server level. Instead of configuring security for each data source (e.g., a data warehouse, a data lake, an on-premise database), you can manage user roles and permissions at the Arrow Flight SQL server. This provides a single point of control and enforcement, ensuring consistent data security and simplifying compliance.
3. Pushing processing closer to Data and Empowering Lightweight, High-Performance Tools
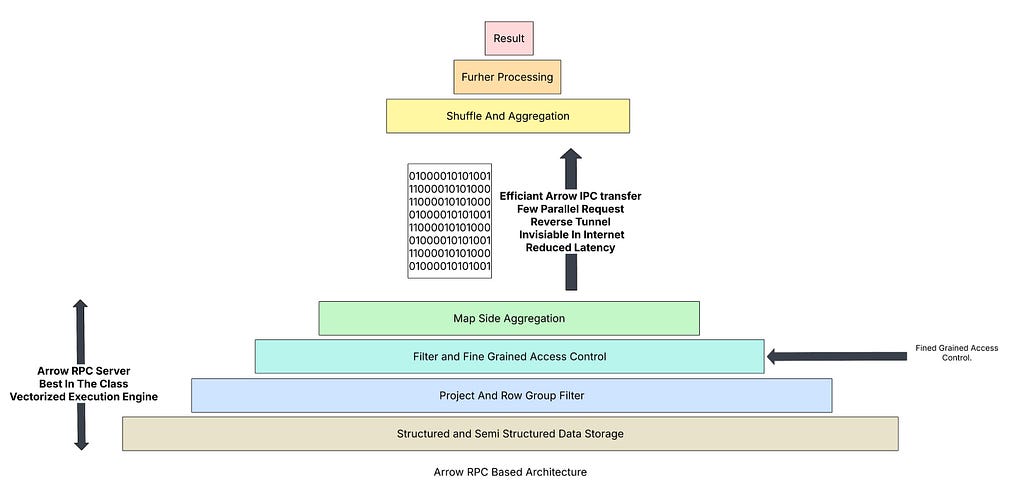
Volcano Data Processing Model
- The Problem: We should be performing majority of processing closer to Data and not push data to where expensive processor are. Generally data processing cluster are expensive whereas Flight Server can run on cheap commodity hardware requiring minimum maintenance.
- Volcano Model: All the SQL processing engines follow Volcano Model where data get reduced at each layer. With Arrow RPC based architecture the bottom layers( Arrow RPC servers) significantly reduces the data leaving much smaller data to be processed by higher level engines such as DuckDB and Polars to do the advanced processing
- The Arrow Flight SQL Solution: An Arrow Flight SQL server already petabyte-scale data to few MBs in a columnar, Arrow-native format. Lightweight tools like DuckDB and Polars are already optimized to read and process this format with incredible speed. They can connect to the server and pull the exact data they need directly into memory, where their vectorized engines can go to work. This unlocks the full power of these tools, allowing them to perform complex, in-memory analytics on massive datasets without needing a massive, resource-hungry distributed engine on the client side. This translates to massive cost savings because a single, powerful machine can now handle analytical workloads that previously required an entire cluster.
4. Statelessness, Scalability, and Manageability
This architectural choice simplifies operations and improves resilience.
- Statelessness: The Arrow Flight SQL server itself is generally stateless in a transactional sense. It doesn’t maintain session-specific state between requests. This means that any server instance can handle any incoming request.
- Scalability: This statelessness makes scaling incredibly easy. You can simply add or remove server instances behind a load balancer to match demand. There’s no complex state synchronization or cluster management required for the servers themselves, which is a major pain point in traditional distributed systems.
- Manageability: Because the servers are stateless and the protocol is standardized, a single, general-purpose driver can connect to any of them. This simplifies client-side development and allows for easier monitoring and troubleshooting.
This architecture, though it adds a layer, ultimately simplifies and supercharges the entire data stack by standardizing data transfer on a modern, high-performance protocol. It’s a fundamental shift from a world of “monolithic” data platforms to a “composable” data ecosystem.
Got questions or thoughts? Drop them in the comments — I’d love to hear from you! 💬 And if this post was helpful, don’t forget to share it with your friends 🚀✨
Curious to dive deeper? Here are some of my past stories that connect with this one 👇
Scaling DuckDB: A Modern Architecture for Analytical Data Applications
https://medium.com/@tanejagagan/why-s3-may-not-be-cheap-after-all-dc03e6e38424