Detecting Similar SQL Queries Using DuckDB


Query Fingerprinting
Consider these two SQL queries:
SELECT c1, c2 FROM t WHERE c3 = 1 AND c4 = 'str1';
SELECT c1, c2 FROM t WHERE c3 = 2 AND c4 = 'str2';
Often, such queries are generated programmatically based on user input. While they share a structural similarity, detecting this resemblance is challenging.
Query fingerprinting offers a solution. This technique identifies similar queries by abstracting away literal values and generating a hash of the resulting normalized query. In the examples above, removing literals yields:
SELECT c1, c2 FROM t WHERE c3 = ? AND c4 = ?;
Hashing this normalized form produces a consistent fingerprint, regardless of the original literal values.
However, reliably replacing literals without a dedicated SQL parser is complex. Fortunately, DuckDB’s json_serialize_sql function and JSON manipulation capabilities provide an elegant workaround.
The process involves:
- Parsing with json_serialize_sql: DuckDB converts the SQL query into a structured JSON representation.
SELECT json_serialize_sql('SELECT c1, c2 FROM t WHERE c3 = 1 AND c4 = ''str1'');
- JSON Tree Manipulation: This JSON is parsed into a tree structure, allowing for easy replacement of all literal values with a placeholder.
JsonNode tree = objectMapper.parser(sql)
JsonNode transformedTree = Transformations.transform(tree, matchFunction, removeLiteralFunction)
- Fingerprint Generation: The modified JSON tree is then hashed to generate the query’s fingerprint.
generateSHA256(transformedTree.toString())
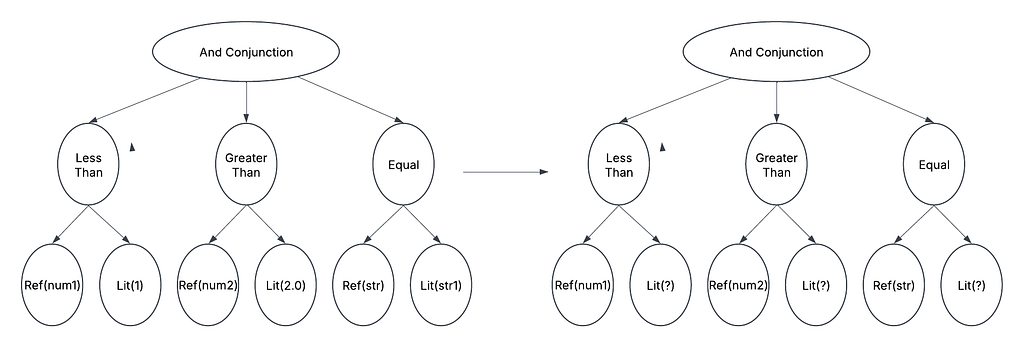
Generation and Manipulation of Where Clause
In our example, both queries would produce the same fingerprint, say “0b77d15856e92dc13…” effectively identifying their similarity.
Having the ability to dissect and modify SQL queries unlocks a wealth of possibilities. The powerful combination of SQL parsing, tree generation, and manipulation enables sophisticated query rewrites and optimizations. Let’s explore a practical example where this capability intersects with data statistics.
Consider a table t with columns c1, c2, and c3, partitioned across two files:
file1:
c1, c2, c3
1, 101, str01
2, 102, str02
3, 103, str03
file2:
c1, c2, c3
11, 111, str11
12, 112, str12
13, 113, str13
Typically, a statistics table (stat_t) accompanies such data, storing metadata like:
stat_t:
filename, c1_min, c2_min, c3_min, c1_max, c2_max, c3_max
file1, 1, 101, str01, 3, 103, str03
file2, 11, 111, str11, 13, 113, str13
Now, examine the query:
SQL
SELECT * FROM t WHERE c1 = 2;
To optimize execution, the query engine first determines which files potentially contain relevant data. This is achieved by querying the statistics table. We can leverage DuckDB’s based tool for query manipulation to dynamically generate this statistics query:
SQL
SELECT filename FROM stat_t WHERE c1_min <= 2 AND c1_max >= 2;
Using DuckDB’s JSON parsing, we can extract the WHERE c1 = 2 clause from the original query, and generate the stat query.
Based on the stat_t data, this query returns file1. Consequently, the engine only needs to scan file1, significantly reducing I/O overhead. This is one of the major optimization provided by data formats such as Apache Iceberg and Delta Lake.
While query manipulation has historically been the domain of specialized, dependency-laden libraries, DuckDB offers a practical and simplified alternative. Learning to generate and manipulate query trees opens up a world of opportunities, allowing developers to implement innovative solutions
You can find the code for example discussed in this write up at
GitHub - tanejagagan/sql-commons
DuckDB SQL to/from JSON
https://duckdb.org/docs/stable/data/json/sql_to_and_from_json.html